
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 최적화
- 심층신경망
- frontend
- React
- Kaggle
- do it
- docker
- 대감집 체험기
- 캐글
- 대감집
- Machine Learning
- bigquery
- 프론트엔드
- 머신러닝
- 클러스터링
- Kubernetes
- 구글
- 리액트
- r
- python
- ADP
- DBSCAN
- ADP 실기
- 타입스크립트
- 쿠버네티스
- LDA
- TooBigToInnovate
- 파이썬
- 차원 축소
- 빅쿼리
- Today
- Total
No Story, No Ecstasy
[ADP 실기 with R] 2. 차원 축소: PCA, LLE, FA (Factor Analysis), MDS 본문
[ADP 실기 with R] 2. 차원 축소: PCA, LLE, FA (Factor Analysis), MDS
heave_17 2020. 12. 12. 17:15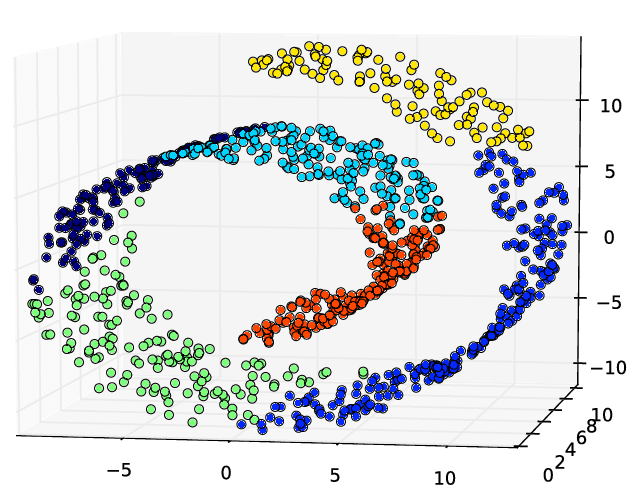
0. 차원 축소
- Feature 수를 크게 줄이는 것으로, 모델의 훈련 속도를 높이거나 데이터 시각화를 위해 사용된다.
- Feature 수가 늘어날수록 샘플의 밀도는 기하급수적으로 낮아진다. (=과대 적합 위험이 커진다.)
- 투영과 매니폴드 학습 접근법
- 투영: 저차원 부분공간(평면)에 놓여 있다고 가정하여, 저차원으로 투영시키는 것
- 매니폴드 학습: 휘어지거나 뒤틀린 저차원 공간에 놓여있다고 가정하여 매니폴드 공간을 찾는 것
1. PCA (Principal Component Analysis)
- 저차원의 초평면에 훈련 세트를 투영시키는 차원 축소 알고리즘이다.
- 분산이 최대로 보존되는 축(원본 데이터 셋과 투영된 것 사이의 평균제곱거리를 최소화)을 찾아야 한다.
- 주성분은 특잇값 분해(SVD)라는 표준 행렬 분해 기술을 통해 찾는다.
- 압축을 위해 사용하기도 하고, 대용량 데이터 처리를 위한 점진적/랜덤 PCA도 개발되었다.
- 매니폴드에 가까운 데이터셋을 투영하기 위한 커널 PCA도 개발되었다.
- R 코드 예제
# 0. 별도의 package import 필요 없음
# 1. PCA 수행
pca.result = princomp(data, cor = T)
# 2. 주성분의 importance 확인 및 절단점 설정
summary(pca.result) #importance 확인 (보통 80% 정도까지 설명되면 Ok)
screeplot(pca.result, npcs = 4, type = "lines") #기울기가 완만해지는 지점으로 절단점 선정
# 3. 각 변수가 각 주성분에 미치는 가중치 확인
loadings(pca.result)
# 4. 주성분 좌표로 표현한 데이터 확인
pca.result$scores
# 5. 행렬도 확인
pca.result = prcomp(data, center = T, scale. = T)
biplot(pca.result, scale = 0)* princomp(), prcomp() 둘 다 큰 차이가 없다. 굳이 차이가 있다면 다음과 같다.
"When scaling the training data, prcomp uses N−1 as denominator but princomp uses N as its denominator."
stats.stackexchange.com/a/172410
What is the difference between R functions prcomp and princomp?
I compared ?prcomp and ?princomp and found something about Q-mode and R-mode principal component analysis (PCA). But honestly – I don't understand it. Can anybody explain the difference and maybe e...
stats.stackexchange.com
2. LLE (Locally Linear Embedding)
- 비선형 차원 축소 기술로서, 투영에 의존하지 않는 매니폴드 학습이다.
- 가까운 k개의 이웃들로부터 선형적으로 연관된 정도를 측정하여, 관계가 가장 잘 보존되는 저차원 표현을 찾는다.
- 대량 데이터에 적용은 어렵다.
- R 코드 예제
# 0. package import
library(lle)
# 1. 주변 이웃을 구성하고, 가중치를 계산
## - m: intrinsic dimension of the data
## - reg: regularisation method (보통 L2로 설정)
lle.neighbors = find_nn_k(data, k = 15)
lle.weights = find_weights(lle.neighbors, data, m = 2, reg = 2)
# 2. lle 수행
## - ss: a logical values indicating wheather to perform subset selection
## - id: a logical values indicating wheather to calculate the intrinsic dimension
## - v: threshold parameter for intrinsic dimension
lle.result = lle(data, m = 2, k = 15, reg = 2, ss = FALSE, id = TRUE, v = 0.9)
# 3. plotting
plot(lle.result$Y, xlab = expression(y[1]), ylab = expression(y[2]))
# 4. lle 좌표로 표현한 데이터 확인
pca.result$Y* www.rdocumentation.org/packages/lle/versions/1.1
3. FA (Factor Analysis)
- Features 중에서 잠재된 요인(factor)을 찾아 그 요인으로 데이터를 표현하는 기법
- 수행 목적:
(1) Feature 간 상관관계 파악 > 다중공선성으로 인한 문제 해결
(2) 다수의 Features를 하나의 Feature(잠재 변수)로 요약 > 차원 축소
- R 코드 예제
# 0. package import
library(psych)
# 1. 요인 개수 정하기
fa.cor = cor(data, use = "pairwise.complete.obs")
scree(fa.cor, factors = F) #보통 eigenvalue >= 1 정도 선에서 끊음 (a factor with an eigenvalue of 1 accounts for as much variance as a single variable)
# 2. FA 수행
## - rotate: varimax, quartimax, ..... (보통 분산을 최대화하는 직교회전방법 varimax를 사용)
fa.result = fa(data, nfactors = 2, n.bos = N, rotate = "varimax")
# 3. FA 결과 확인 (참고: https://maengdev.tistory.com/163)
fa.result$RMSEA # Root Mean Square Error of Approx.: 0.05 이하면 좋은 적합도라고 판단
fa.result$TLI #Turker-Lewis Index: 0.90 이상이면 좋은 적합도라고 판단
fa.plot(fa.result) #새로운 좌표 시각화
fa.result$loadings
fa.diagram(fa.result) #feature - factor 관계 시각화
4. MDS (Multi-Dimensional Scaling)
- 데이터 간 유사성을 기반으로 2/3차원 공간 상에 데이터를 표현 (최대한 데이터 간 거리/유사성 유지)
- PCA와는 다르게 차원 축소와 더불어, 원 데이터의 정보를 최대한 보존하는 것이 목적이다.
- 연속형 데이터는 계량적 MDS, 비연속형 데이터는 비계량적 MDS 수행
- 잘 정리된 링크: wujincheon.github.io/wujincheon.github.io/machine%20learning/2018/10/23/pca&mds.html
Data Science|Principal Component Analysis(PCA) & MultiDimensional Scaling(MDS)
23 Oct 2018 Principal Component Analysis(PCA) & MultiDimensional Scaling(MDS) 차원축소 기법 중, Linear Embedding에 해당하는 PCA(주성분분석)과 MDS(다차원척도법)에 대한 개념과 알고리즘, 그리고 적용을 통해 자세히
wujincheon.github.io
- R 코드 예제
# 0. 별도의 package import 필요 없음
# 1. MDS 수행
mds.result1 = cmdscale(data) #연속형
mds.result2 = isoMDS(data)
# 2. 결과 확인
mds.result1$points
mds.result1$stress


