
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 빅쿼리
- 심층신경망
- 프론트엔드
- bigquery
- React
- 파이썬
- 타입스크립트
- 클러스터링
- frontend
- python
- do it
- 리액트
- ADP 실기
- r
- 최적화
- ADP
- 쿠버네티스
- 차원 축소
- LDA
- TooBigToInnovate
- 캐글
- 머신러닝
- Kaggle
- 대감집
- Machine Learning
- DBSCAN
- 구글
- Kubernetes
- 대감집 체험기
- docker
- Today
- Total
No Story, No Ecstasy
[ADP 실기 with R] 8. 성과 분석: Confusion Matrix, ROC Curve, AUROC 본문
[ADP 실기 with R] 8. 성과 분석: Confusion Matrix, ROC Curve, AUROC
heave_17 2020. 12. 12. 17:211. Confusion Matrix
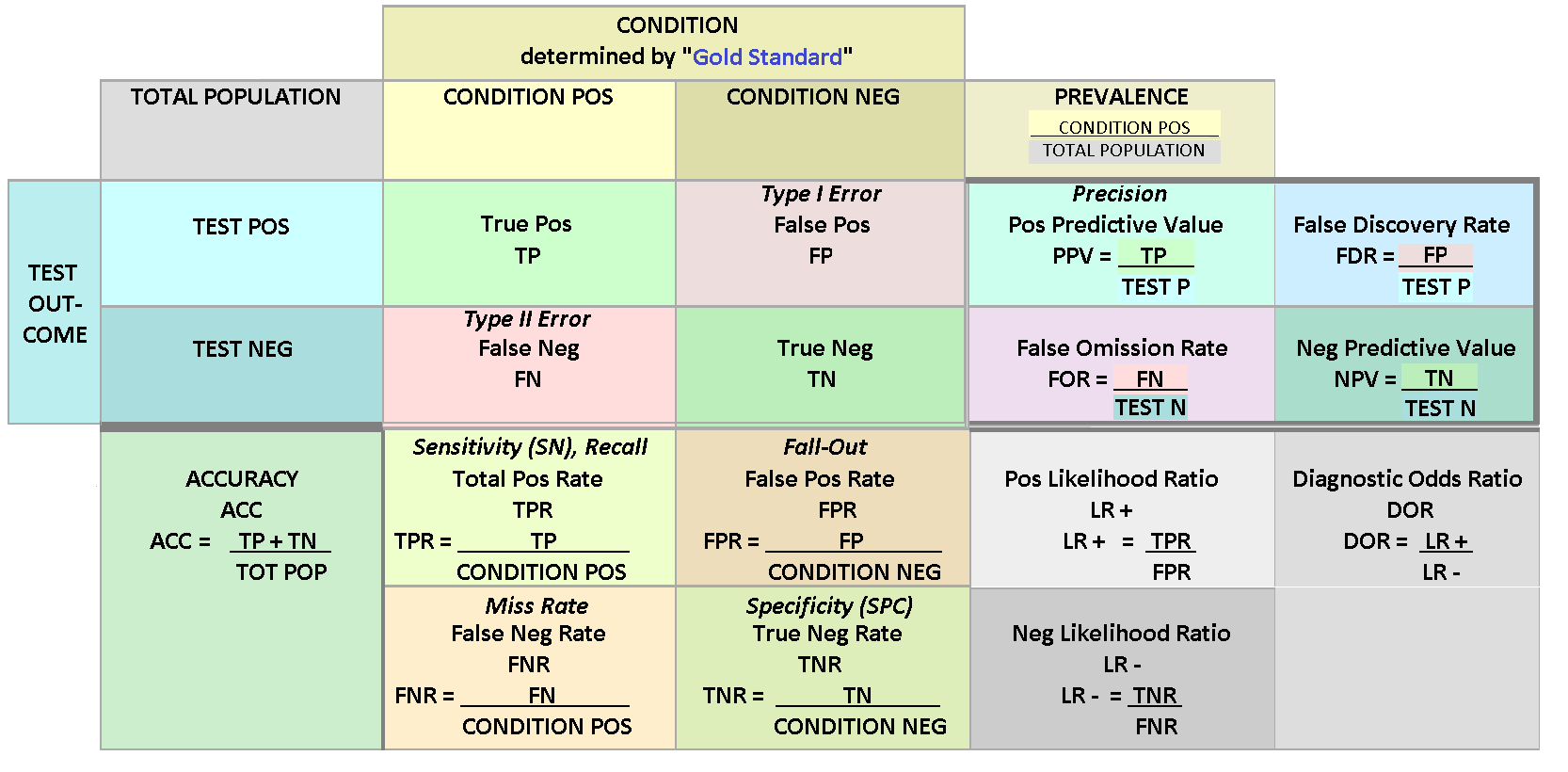
- F1 score: 2 x Precision x Recall / (Precision + Recall) = 2 / (1/Precision + 1/Recall)
- Accuracy는 imbalanced data에서 부정확한 판단을 하게 될 수 있다
- Imbalanced data에 대한 성과 분석을 위해 precision과 Recall을 사용하는 것이 F1 score다.
- F1 score는 두 지표의 조화평균을 사용하여 모델을 평가한다. (조화평균은 두 값이 비슷할 경우 높은 값을 가짐)
- 잘 정리된 링크: 89douner.tistory.com/174
12. Precision, Recall, F1 score (Feat. TP, FP, FN, TN)
안녕하세요 이번글에서는 CNN 모델을 평가하는 또 다른 지표인 F1 score에 대해서 알아보도록 할거에요. 앞서 "5.CNN 성능은 어떻게 평가하게 되나요?"라는 글에서 봤듯이 CNN은 accuracy 기반을 하여 CNN
89douner.tistory.com
- R 코드 예제
# 0. package import
library(caret)
library(ROCR)
# 1. confusion matrix 그리기
cm = confusionMatrix(predicted_data, reference_data, positive = "1")
cm
# 2. 분할표 그리기
xtabs(~predicted + reference)
# 3. 성과 확인
cm$byClass["Precision"]
cm$byClass["Recall"]
cm$byClass["F1"]
2. ROC (Receiver Operating Characteristic) Curve, AU (Area Under) ROC
- ROC Curve: 가로축을 FPR (1 - Specifity), 세로축을 TPR (Sensitivity)로 두어 시각화한 그래프 (2진 분류에만 적용됨)
- AUROC: ROC Curve 아래 면적 (0.6: Fail / 0.7: Poor / 0.8: Fair / 0.9: Good / 1.0: Excellent)


- R 코드 예제
# 0. package import
library(caret)
library(ROCR)
# 1. ROC curve 그리기
roc.pred = prediction(as.numeric(predicted), as.numeric(reference))
plot(performance(roc.pred, "tpr", "fpr")
# plot(performance(pred, "prec", "rec")) > precision - recall curve
abline(a = 0, b = 1, lty = 2, col = "black")
# 2. AUROC 구하기
performance(roc.pred, "auc")@y.values'Data Science Series' 카테고리의 다른 글
| [ADP 실기 with R] 10. 시계열 분석 (Time Series Analysis) (0) | 2020.12.12 |
|---|---|
| [ADP 실기 with R] 9. 연관분석: Apriori, FP-Growth (0) | 2020.12.12 |
| [ADP 실기 with R] 7. Neural Networks (0) | 2020.12.12 |
| [ADP 실기 with R] 6. 분류 분석 (2): Ensemble (Bagging, Boosting, Random Forest) (0) | 2020.12.12 |
| [ADP 실기 with R] 5. 분류 분석 (1) : Logistic Regression, Decision Tree, Naive Bayesian, kNN, SVM, LDA (0) | 2020.12.12 |



