
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- do it
- DBSCAN
- python
- bigquery
- 리액트
- 파이썬
- frontend
- docker
- ADP 실기
- r
- 대감집 체험기
- 머신러닝
- Kubernetes
- LDA
- 심층신경망
- 빅쿼리
- 쿠버네티스
- Kaggle
- 프론트엔드
- 타입스크립트
- 차원 축소
- React
- 최적화
- 클러스터링
- 캐글
- 대감집
- TooBigToInnovate
- Machine Learning
- ADP
- 구글
Archives
- Today
- Total
No Story, No Ecstasy
[ADP 실기 with R] 6. 분류 분석 (2): Ensemble (Bagging, Boosting, Random Forest) 본문
Data Science Series
[ADP 실기 with R] 6. 분류 분석 (2): Ensemble (Bagging, Boosting, Random Forest)
heave_17 2020. 12. 12. 17:19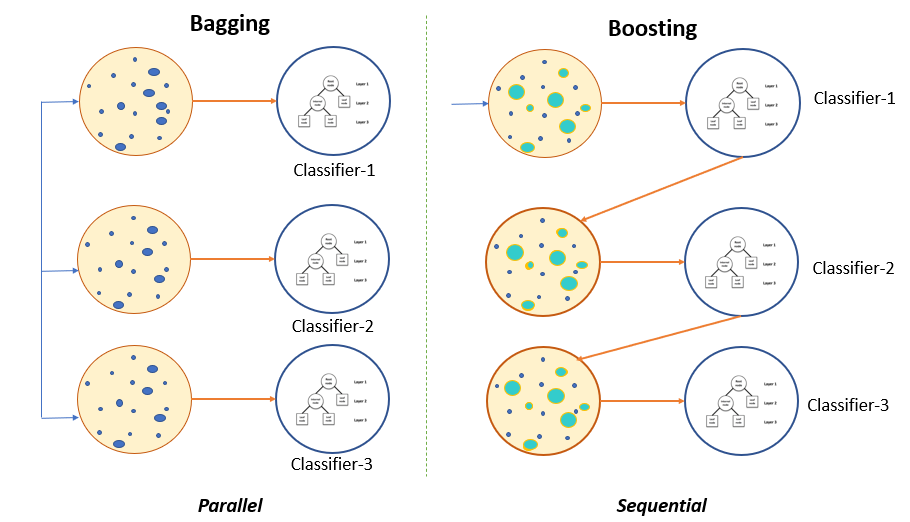
0. Ensemble
- 주어진 데이터로부터 여러 개의 예측 모형들을 만든 후 조합하여 하나의 최종 예측 모형을 만드는 기법
1. Bagging
- Bootstrap을 활용하여 여러개의 예측모형을 만든 후 결합하여 최종 예측 모형을 만드는 기법
- 여러 예측 모형들의 Voting을 통한 다수결로 분류 결과를 결정한다.
- R 코드 예제
# 0. package import
library(adabag)
# 1. bagging 모델 생성
## - mfinal: the number of trees to use (= the number of iterations for which bootstrapping is run)
bg.model = bagging(y~., train_data, mfinal = 15,
control = rpart.control(maxdepth = 5, minsplit = 15))
# 2. 모델과 test_data를 활용하여 예측
bg.predict = predict(bg.model, test_data, type = "prob")
2. Boosting
- 여러 개의 예측 모형들을 결합하여 하나의 강한 예측 모형을 만드는 기법
- 각 예측 모형들에 맞는 가중치를 찾아 결합된 최종 모형이 도출된다.
- Adaboosting, Gradient boosting 방법이 가장 대표적
- R 코드 예제
# 0. package import
library(adabag)
# 1. boosting 모델 생성
## - mfinal: the number of models to use
## - boos: using the weights for each observation on that iteration
bs.model = boosting(y ~ ., boos = FALSE, mfinal = 15,
control = rpart.control(maxdepth = 5, minsplit = 15))
# 2. 모델과 test_data를 활용하여 예측
bs.predict = predict(bs.model, test_data, type = "prob")
3. Random Forest
- Bootstrapping과 feature selection을 통해 약한 분류기들을 생성 후, 선형결합하여 최종 모형을 만드는 기법
- Feature selection은 트리를 더욱 다양하게 만듦으로써, 편향을 손해보는 대신 분산을 낮추어 예측률을 높여준다.
- Feature Importance를 측정할 수 있다. (어떤 특성을 사용한 노드가 불순도를 얼마나 감소시키는지 확인)
- R 코드 예제
# 0. package import
library(randomForest)
# 1. randomForest 모델 생성
## - importance = T: 변수 중요도 확인
## - https://www.rdocumentation.org/packages/randomForest/versions/4.6-14/topics/randomForest
rf.model = randomForest(y~., train_data, importance = T)
# 2. 모델과 test_data를 활용하여 예측
rf.predict = predict(rf.model, test_data, type = "class")'Data Science Series' 카테고리의 다른 글
'Data Science Series' Related Articles
more



