
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 대감집
- LDA
- ADP 실기
- 쿠버네티스
- Kubernetes
- 차원 축소
- ADP
- 구글
- DBSCAN
- 프론트엔드
- TooBigToInnovate
- 타입스크립트
- 대감집 체험기
- 최적화
- 빅쿼리
- bigquery
- 심층신경망
- r
- python
- Machine Learning
- 머신러닝
- React
- 파이썬
- frontend
- Kaggle
- docker
- do it
- 클러스터링
- 캐글
- 리액트
- Today
- Total
No Story, No Ecstasy
자연어 처리 - Transformer, Bert, GPT-3 본문
1. Transformer
. 자연어 처리 분야에서 기존 RNN 계열의 모델들이 갖고 있던 문제를 해결해줌
. 기존의 순차적인 연산에서 벗어나 병렬처리가 가능한 모델로 우수한 성능을 보임
. Multi-head self-attention을 이용해 순차적 연산을 줄이고, 더 많은 단어들 간 dependency를 모델링하는 게 핵심
. 대표적인 모델이 BERT (Bidirectional Encoder Representations from Transformers)
. 2020년에는 기존 GPT 모델의 크기를 비약적으로 키운 GPT-3가 등장
. BERT와 달리 GPT-3는 디코더 기반 fine-tuning이 필요 없음
. Few-Shot Learning만으로도 응용 태스크에서 우수한 성능을 달성함
2. 기계번역 신경망 발전 과정
. 2021년 기준으로 최신 고성능 모델들은 Transformer 아키텍처를 기반으로 하고 있음
. GPT: Transformer의 디코더 아키텍처를 활용
. BERT: Transformer의 인코더 아키텍처를 활용
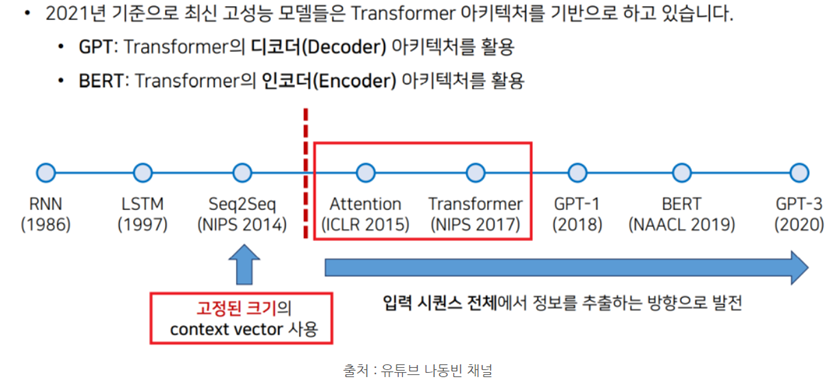
(1) Seq2Seq 모델
. 인코더와 디코더를 가지는 RNN 구조
. 인코더가 RNN을 통해 입력을 벡터로 만들고, 디코더가 RNN을 통해 벡터를 출력으로 만듦
. 고정된 크기의 Context Vector를 사용함 (중요한 특성만 골라서 활용함)
. 필연적으로 정보의 손실이 발생하여 성능이 저하되고, 속도도 매우 느림
(2) Attention
. Seq2Seq 모델에서 발생하는 정보 손실 문제를 해결하기 위해 등장함
. 인코더에서 문장 정보를 모은 다음 디코더로 보내는 것이 아닌, 단어 별로 전부 보내는 방식
. 즉, 인코더에서 나오는 Hidden state의 값을 모두 디코더에서 받아냄
. 즉, 디코더가 문장 중 어떤 단어에 특히 집중해서 출력을 만들지 고민할 수 있게 됨
. 각 스텝의 hidden state마다 점수를 매기고, 이 것의 softmax 값을 각 스텝의 hidden states에 곱해서 더한다.
. 높은 점수를 가지는 hidden state가 더 큰 부분을 차지하게 된다.
. 이 과정은 decoder가 단어를 생성하는 매 스텝마다 반복된다.
. 뿐만 아니라, 시각화를 통해 출력이 어떤 입력 정보를 참고했는지 쉽게 이해할 수 있게 됨
(3) Transformer
. 기존에 Attention은 RNN에서 인코더가 입력을 벡터로 압축시 일부 정보가 손실되는 것을 보정하는 용도로 활용됨
. Transformer에서는 Attention 메커니즘이 인코더와 디코더를 만드는데 직접적으로 사용됨
![]()
- 인코딩 과정
. 보통 자연어 처리를 위해서는 워드 임베딩을 통해 문장을 벡터로 바꿔야 함 (단어 간 유사도 판별이 가능해짐)
. Transformer는 RNN을 사용하지 않기에, 단어 순서에 대한 정보를 얻을 수 없음
-> 단어들의 위치 정보를 포함하는 임베딩인 Positional Encoding을 추가함
. Self-Attention을 통해 입력 문장 내 각 단어의 연관성을 학습하여 문맥 정보를 익히게 함
. 어텐션을 수행하고 나온 값과 Residual Connection을 통해 나온 값을 받아서 정규화 수행
(학습 속도를 높이고, Local Optimum 문제에 빠지는 가능성을 줄이기 위해 사용)
. 여기서 나온 값을 일반적인 신경망에 넣고 학습 후 다시 정규화 과정을 거치면 1st Encoding 종료
. 이 과정을 하나의 layer라고 하며, 개발자들이 몇 개의 layer를 가질지 설명할 수 있음
- 디코딩 과정
. 인코더와 마찬가지로 여러 개의 layer로 구성됨
. 가장 마지막 인코더에서 나온 출력값이 입력으로 들어감
. 디코더 또한 Positional Encoding이 입력에 추가됨
. 2개의 Attention이 사용됨
(1) Self-Attention: 출력 단어들 스스로에 대한 관계 값을 계산
(2) Encoder-Decoder Attention: 출력될 단어들이 입력된 단어들과 어떻게 연관되었는지 계산
-> 매 단어 출력마다 입력 소스 문장 중 초점을 두어야 하는 단어를 찾는다.
. Residual 값 반영 및 정규화, Feedforward Layer 등을 진행하고, Linear와 출력함수 작업 후 최종문장 출력
. 즉, 마지막 인코더 레이어의 출력은 모든 디코더 레이어에 들어가며, 서로 같은 개수의 layer를 갖는다.
. RNN/LSTM과의 가장 큰 차이점
. 입력 단어 개수만큼 hidden state를 만들지 않고, 문장 정보가 한 번에 보내진다.
-> 계산 복잡도는 낮아지고, 순환 연산이 아닌 어텐션 레이어들을 쌓는다.
(4) BERT
. 라벨링되지 않은 대용량 데이터로 모델을 미리 학습시킨 뒤, 특정 태스크의 라벨링된 데이터로 전이학습하는 모델
. ELMo나 GPT 등도 BERT와 유사하나, 이들은 입력 문장을 거의 단방향으로만 학습시켰음
. 또한 사전학습 모델의 fine-tuning만을 통해 당시 최고 수준을 달성함
. ***트랜스포머 기반, 사전학습과 미세조정 시의 아키텍처를 조금 다르게 하여 전이학습을 용이하게 만듦
. BERT의 사전학습 모델은 트랜스포머의 인코더 부분만 쌓아올린 구조다.
. 미세조정 방법은 2가지가 있다.
1. Feature-based: 추가적인 특정 작업을 할 수 있도록 새로운 사전학습 모델을 추가 (ELMo)
2. Fine-tuning: Task 특화 파라미터를 최대한 줄이고, 전체 신경망의 가중치를 조정 (지도학습이다)

. BERT 학습 방법
(1) 기존 방법: 이전 단어들로부터 다음 단어를 예측하는 단방향 기법
* ELMo는 정방향 LSTM과 역방향 LSTM을 이어붙여서 이를 극복하고자 했지만 미미했음
(2) MLM (Masked Language Model)
. MLM은 문장 내 일부 단어를 가리고, 문맥을 통해 어떤 단어가 들어갈지 맞추는 학습 방법
. 마스킹된 단어의 앞 뒤 토큰을 모두 고려하기 때문에 양방향성을 가진다고 볼 수 있음
(3) NSP (Next Sentence Prediction)
. 주어진 문장 다음에 두가지 문장을 제시하여, 둘 중 어느 문장이 문맥상 이어질지 맞추는 방법
(4) 임베딩 방식
. 워드 임베딩과 캐릭터 임베딩을 섞은 방식을 활용
. 일단 토큰 단위로 분리하되, 자주 나오는 글자들은 병합하여 하나의 토큰으로 만든다. (형태소 분석 필요 없어짐)
. MLM/NSP를 수행하여 사전학습을 하기 위해서 인풋을 3개의 임베딩의 합으로 표현
1. Token 임베딩: 실질적인 입력이 되는 임베딩
2. Segment 임베딩: 두 개의 문장을 구분
3. Position 임베딩: 위치 정보 학습
(5) GPT-3
. GPT (Generative Pre-trained Transformer) 모델의 크기를 비약적으로 키운 모델
. 사후 학습 없이 Few-shot 학습만으로도 응용 태스크에서 우수한 성능을 보여 큰 화제를 일으킴
. GPT 모델은 트랜스포머 디코더 일종으로 입력 텍스트의 다음 단어를 예측하는 모델
. BERT vs GPT-3
. Fine-tuning할 데이터가 충분히 많다면, BERT가 더 적합할 수 있다.
. https://medium.com/swlh/understanding-gpt-3-openais-latest-language-model-a3ef89cffac2
Understanding GPT-3: OpenAI’s Latest Language Model
1. Introduction
medium.com

'Data Science Series' 카테고리의 다른 글
| Ad Segments beyond Look-alike Audience Model (0) | 2021.09.07 |
|---|---|
| Attention 메커니즘 (0) | 2021.05.30 |
| 오토인코더 (Autoencoder) (0) | 2021.05.30 |
| 심층 신경망 (DNN) 훈련 (0) | 2021.05.29 |
| 토픽 모델링 - LDA, Mallet LDA, Guided LDA (0) | 2021.05.27 |
