
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 구글
- 프론트엔드
- 타입스크립트
- 머신러닝
- docker
- 대감집 체험기
- r
- 캐글
- 차원 축소
- 파이썬
- 대감집
- React
- LDA
- TooBigToInnovate
- 리액트
- Kubernetes
- frontend
- DBSCAN
- do it
- 심층신경망
- 쿠버네티스
- Kaggle
- ADP 실기
- python
- bigquery
- Machine Learning
- 최적화
- 클러스터링
- 빅쿼리
- ADP
- Today
- Total
No Story, No Ecstasy
심층 신경망 (DNN) 훈련 본문
1. Vanishing Gradient (or exploding gradient) 문제 해결
- Vanishing Gradient란?
. 알고리즘이 하위층으로 진행될수록 그래디언트는 점점 작아지게 된다(연쇄적으로 계산하기 때문).
. 어떤 경우에는 특정 층의 가중치가 비정상적으로 커져서, 알고리즘이 발산할 수도 있다. (예: RNN)
. 심층 신경망이 오랫동안 방치되었던 이유 중 하나
- 중요한 발견: 로지스틱 시그모이드 함수와 표준정규분포를 사용한 가중치 무작위 초기화의 문제
. 이 조합으로 훈련 시, 각 층에서 출력의 분산이 입력의 분산보다 크다는 것을 발견
. 신경망의 위쪽으로 갈수록 분산이 계속 커져 가장 높은 층에서는 활성화 함수가 0이나 1로 수렴
. 로지스틱 함수의 평균이 0.5라는 사실 때문에 더 나빠진다. (로지스틱은 항상 양수를 출력 -> 가중치의 합이 커질 가능성이 높음)
즉, 가중치 초기화와 활성화 함수를 개선하면, 더 좋은 심층 신경망 모델을 얻을 수 있다.
1.1. 세이비어 초기화와 He 초기화
. (정방향) 신호가 죽거나 폭주하지 않고, 적절히 흐르기 위해서는 각 층의 출력, 입력의 분산이 같아야 한다.
. (역방향) 층을 통과하기 전과 후의 크래디언트 분산이 동일해야 한다.
. 이를 위한 세이비어(글로럿) 초기화가 제안됨 (input, output의 분산을 동일하게 만들고, 훈련 속도를 상당히 높일 수 있다)
. ReLU 활성화 함수를 위한 He 초기화 전략도 등장함

1.2. 수렴하지 않는 활성화 함수의 사용
. 심층 신경망에서는 ReLU가 정통적인 시그모이드 함수보다 훨씬 더 잘동작하는 것이 밝혀졌다.
. But, 죽은 ReLU 문제를 가진다. (일부 뉴런이 0 이외의 값을 출력하지 않게 되는 현상)
. 문제 해결을 위해 Leaky ReLU와 같은 변종 ReLU 함수를 사용하게 되었다. LeakyReLU(z) = max(az, z)
. ELU (Exponential Linear Unit) 활성화 함수가 다른 모든 ReLU 변종의 성능을 앞섰다. (테스트시 성능은 느림)

1.3. 배치 정규화
. ELU, He 초기화 사용은 훈련 초기 단계에서 Gradient 소실/폭주 문제를 크게 감소시키지만, 아예 없어진다고 보장할 수 없다.
. 배치 정규화를 통해 이를 해결하고자 했다. (각 층에서 활성화 함수를 통과하기 전에 모델에 연산을 하나 추가한다.)
. 입력 데이터의 평균을 0으로 정규화 > 2개의 파라미터를 활용해 스케일을 조정하고 평행이동시킴
. 정규화를 위해 평균과 표준편차를 추정할 때 현재 미니배치에서 입력의 평균과 표준편차를 활용한다.
. 각 층마다, 스케일, 이동, 편균, 표준편차 4개의 파라미터가 학습된다.
. 훈련 과정에 잡음을 넣는 것이기 때문에, 훈련 세트에 과대적합되는 것을 방지하는 규제의 효과도 가진다.
. But, 모델의 복잡도가 상승되고, 실행 시간도 늘어난다.

1.4. 그래디언트 클리핑
. 역전파 시, 일정 임곗값 이상을 잘라내는 방법이다. (RNN에서 일반적으로 널리 사용됨)
2. Gradient Descent 기법에 비해서 훈련 속도를 크게 높여주는 최적화 방법
2.1. 미리 훈련된 층 재사용하기
. 해결하려는 문제와 비슷한 유형의 문제를 처리한 신경망이 있다면, 하위층을 재사용하는 것이 좋다. (Transfer Learning)
. 훈련 속도를 크게 높여줄 뿐만 아니라 필요한 훈련 데이터도 훨씬 적다.
2.1.1. 텐서플로 모델 재사용하기
2.1.2. 다른 프레임워크의 모델 재사용하기
2.1.3. 신경망의 하위층을 학습에서 제외하기
2.1.4. 동결된 층 캐싱하기
2.1.5. 상위층을 변경, 삭제, 대체하기
2.1.6. 모델 저장소 활용하기
2.1.7. 비지도 사전훈련 (제한된 볼츠만 머신, 오토 인코더 등)
2.1.8. 보조 작업으로 사전훈련
2.2. 고속 옵티마이저
. 표준적인 경사 하강법 대신 더 빠른 옵티마이저를 사용할 수 있다.
. 모멘텀 최적화, 네스테로프 가속 경사, AdaGrad, RMSProp, Adam 옵티마이저 등이 있다.
2.2.1. 모멘텀 최적화 (Momentum Optimization)
. 경사 하강법은 가중치에 대한 비용함수의 그래디언트에 학습률을 곱한 것을 차감하여 가중치를 갱신한다.
. 모멘텀 최적화는 이전 그래디언트가 얼마였는지를 상당히 중요하게 다룸
. 매 반복에서 현재 그래디언트에 학습률을 곡한 값을 모멘텀 벡터에 더하고, 이 값을 빼는 방식으로 가중치를 갱신한다.
. 그래디언트를 속도가 아닌 가속도로 활용하는 것
. 모멘텀 최적화가 경사 하강법보다 더 빠르게 평편한 지역을 탈출하게 도와준다.
. 또한, 지역 최적점을 건너뛰도록 하는 데도 도움이 된다.
. 보통 하이퍼파라미터 모멘텀=0.9에서 가장 잘 작동한다.
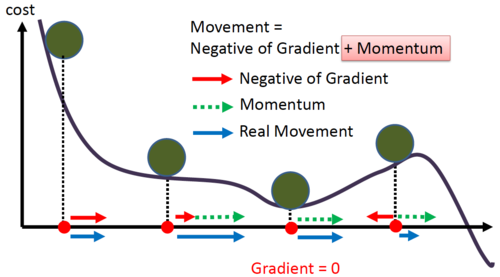

2.2.2. 네스테로프 가속 경사 (Nesterov Momentum Optimization)
. 현재 위치가 아니라 모멘텀의 방향으로 조금 앞서서 비용 함수의 그래디언트를 계산하는 것이다.
. 일반적으로 모멘텀 벡터가 올바른 방향을 가리킬 것이므로 이런 변경이 가능하다.
. 기본 모멘텀 최적화보다 거의 항상 훈련 속도를 높여준다.
2.2.3. AdaGrad
. 가장 가파른 차원을 따라 그래디언트 벡터의 스케일을 감소시켜, 알고리즘이 전역 최적점을 빠르게 찾도록 한다.
. 학습률을 감소시키지만, 경사가 완만한 차원보다 가파른 차원에 대해 더 빠르게 감소된다. (adaptive learning rate)
. 이를 통해 전역 최적점 방향으로 더 곧장 가도록 갱신하는데 도움이 된다.
. 학습률 파라미터를 덜 튜닝해도 된다는 점도 장점이다.
. But, 심층 신경망에서 학습 시 너무 일찍 멈춰 버리는 경향이 있다.
2.2.4. RMSProp
. AdaGrad가 너무 빠르게 느려져서 전역 최적점에 수렴하지 못하는 문제를 해결한 알고리즘
. 훈련 시작부터 모든 그래디언트가 아닌, 가장 최근 반복에서 비롯된 그래디언트만 누적함으로써 문제를 해결했다.
. 감쇠율 하이퍼파라미터 설정이 필요 (보통 0.9에서 잘 작동함)
. Adam 최적화가 나오기 전까지 연구자들이 가장 선호하는 최적화 알고리즘이었다.
2.2.5. Adam 최적화 (Adaptive Moment Estimation)
. 모멘텀 최적화와 RMSProp 아이디어를 합친 방법
. 모멘텀 최적화처럼 지난 그래디언트의 지수감소 평균을 따르고, RMSProp처럼 지난 그래디언트 제곱의 지수감소 평균을 따름
. 보통 beta_1 = 0.9, beta_2 = 0.999로 초기화한다.

2.2.6. 학습률 스케쥴링
. 학습률을 너무 높게 잡으면 발산할 수 있고, 너무 작게 잡으면 시간이 매우 오래 걸릴 수 있다.
. 보통 높은 학습률에서 시작하고 학습 속도가 느려질 때 학습률을 낮추는 방법을 사용한다. 보편적인 방법은 다음과 같다.
(1) 미리 정의된 개별적인 고정 학습률: 매뉴얼하게 epoch에 따라 수정
(2) 성능 기반 스케쥴링: 매 스텝마다 검증 오차를 측정하여, 줄어들지 않으면 학습률을 감소시킨다.
(3) 지수 기반 스케쥴링: 반복 횟수 t의 함수로 학습률을 설정한다. 잘 작동하지만 2개의 하이퍼파라미터를 튜닝해야 한다.
(4) 거듭제곱 기반 스케쥴링: 학습률을 t의 - 거듭제곱으로 설정한다. 지수 기반과 비슷하나 학습률이 훨씬 느리게 감소된다.
3. Overfitting 해결을 위한 규제 방법
. 심층 신경망의 높은 자유도는 훈련 세트에 과대적합되기 쉽다는 것을 의미하기도 한다.
3.1. 조기 종료
. 검증 세트의 성능이 떨어지기 시작할 때 훈련을 중지시킨다.
. 일정 스텝마다 검증 세트로 모델을 평가해서 이전의 최고 성능보다 더 나을 경우 이를 최고 성능의 스냅샷으로 저장
. 최고 성능 스냅샷 이후의 시간이 특정 한계점을 넘으면 훈련을 중지시킨다.
. 다른 규제 기법들과 연결하면 더 높은 성능을 얻을 수 있다.
3.2. L1, L2 규제
. 비용함수에 적절한 규제항을 추가한다.
3.3. 드롭아웃
. 가장 인기 있는 규제 방법
. 매 훈련 스텝에서 각 뉴런은 임시적으로 드롭아웃될 확률 p를 가진다. p: 드롭아웃 비율(보통 50%로 설정)
. 이번 훈련 스텝에는 완전히 무시되지만 다음 스텝에는 활성화될 수 있다.
. 훈련이 끝난 후에는 더 이상 드롭아웃을 적용하지 않는다.
. 입력값의 작은 변화에 덜 민감해지고, 결국 더 안정적인 네트워크가 되어 일반화 성능이 좋아진다.
. 과대적합 -> 드롭아웃 비율을 올린다 / 과소적합 -> 드롭아웃 비율을 낮춘다.
. 네트워크 층이 많을 경우에는 드롭아웃 비율을 높이고, 소규모 네트워크에서는 줄이는 것이 좋다.
. 수렴을 상당히 느리게 만들지만 적절히 튜닝하면 매우 좋은 모델을 얻는 경우가 많다.
3.4. 맥스-노름 규제
. 입력의 연결 가중치 w의 L2 노름이 r 이하가 되도록 제한한다.
. 매 훈련 스텝이 끝나고 w의 L2 노름을 계산 후, w를 클리핑한다.
. 그래디언트 감소/폭주 문제를 완화하는 데 도움을 줄 수 있다.
. 전체 손실함수에 규제 손실항을 추가할 필요가 없다.
3.5. 데이터 증식
. 기존 데이터에서 새로운 훈련 데이터를 인공적으로 생성한다.
. 과대적합을 줄이므로 규제의 방도로 사용된다.
. 만약 이미지 구분 모델을 만든다면, 모든 이미지를 조금씩 이동, 회전하거나 크기를 바꿔서 만든 이미지를 훈련 세트에 추가한다.
'Data Science Series' 카테고리의 다른 글
| 자연어 처리 - Transformer, Bert, GPT-3 (0) | 2021.05.30 |
|---|---|
| 오토인코더 (Autoencoder) (0) | 2021.05.30 |
| 토픽 모델링 - LDA, Mallet LDA, Guided LDA (0) | 2021.05.27 |
| HDBSCAN (Hierarchical DBSCAN) (0) | 2021.05.25 |
| [Kaggle Visualization] Python basic code (0) | 2021.04.28 |


